云计算与并行技术期末复习
云计算与并行技术复习
开卷
1.概述
云计算定义、特点
- 云计算是一种商业计算模型。它将计算任务分布在大量计算机构成的资源池上,使各种应用系统能够根据需要获取计算力、存储空间和信息服务。
- 计算是分布式计算、并行计算、效用计算、网络存储、虚拟化、负载均衡、热备份冗余等传统计算机和网络技术发展融合的产物。
- 云计算是通过网络按需提供可动态伸缩的廉价计算服务。
- 云计算是一种按使用量付费的模式,这种模式提供可用的、便捷的、按需的网络访问,进入可配置的计算资源共享池(资源包括网络、服务器、存储、应用软件、服务),这些资源能够被快速提供,只需投入很少的管理工作,或与服务供应商进行很少的交互。
7个特点:超大规模、虚拟化、高可靠性、通用性、高可伸缩性、按需服务、极其廉
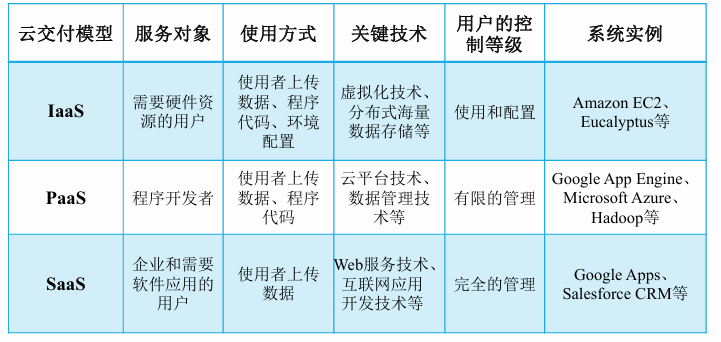
云计算的服务类型,SaaS,PaaS,IaaS
- 将软件作为服务SaaS:一种通过Internet提供软件的模式,用户无需购买软件,而是向提供商租用基于Web的软件。
- 将平台作为服务PaaS:是将服务器平台或者开发环境作为服务进行提供。开发简单、部署简单、维护简单。
- 将基础设施作为服务IaaS:服务提供商将多台服务器组成的“云端”服务(包括内存、I/O设备、存储和计算能力等等)作为计量服务提供给用户。
- 容器即服务CaaS:也称为容器云,是以容器为资源分割和调度的基本单位,封装整个软件运行时环境,为开发者和系统管理员提供用于构建、发布和运行分布式应用的平台。
云部署模式:公有云、私有云、混合云
- 公有云:为外部客户提供服务的云,它所有的服务是供别人使用,而不是自己用。在此种模式下,应用程序、资源、存储和其他服务,都由云服务供应商提供给用户,这些服务多半是免费的,也有部分按需按使用量来付费,这种模式只能使用互联网访问和使用。
- 私有云:企业自己使用的云,它所有的服务不是供别人使用,而是供自己内部人员或分支机构使用
- 混合云:指供自己和客户共同使用的云,它所提供的服务既可以供别人使用,也可以供自己使用。
多租户的概念
- 多租户应用---多个租户共享硬件资源,硬件资源提供一个共享的应用和数据库实例。每个租户认为自己独占资源,因为实例提供高度的定制以满足租户所需。
- 指一个软件实例服务于多个用户的架构。每个用户称为一个租户
- 随着“多租户”在应用架构中实现层次的增高,租户间共享资源也越来越多,资源利用率越来也高,单位资源成本越来越低,租户间的隔离性越来越差。
- 租户间隔离性降低,会导致许多问题:如数据安全性降低, 租户间性能、异常相互影响等 等。
- 在单位资源成本和租户隔离成本取最佳平衡点,就能找到最合理的架构。
云计算的优势
- 减少企业IT的电力和制次成本、管理成本、系统采购成本;大型数据中心减少网络、存储、管理成本;减少电力消耗,平衡区域用电
- 提供弹性的服务,在超大资源池中动态分配和释放资源;云计算平台的规模极大, 比较容易平稳整体负载;资源利用率达到80%左右,是传统模式5~7倍;低成本+高利用率=节约总成本
重要的商用云平台
- 亚马逊云计算:Amazon EC2、Amazon S3、Amazon分布式架构Dynamo
- 谷歌云计算:Google文件系统GFS、分布式数据处理MapReduce、分布式结构化数据表Bigtable
- 其他:微软Windows Azure操作系统、中国移动BigCloud、阿里/腾讯/百度/华为/京东云
虚拟化(掌握基本概念)
虚拟化架构:寄居虚拟化、裸机虚拟化
- 寄居虚拟化:虚拟化层称为虚拟机监控器(VMM)、系统损耗比较大、没有独立的Hypervisor层、操作系统层虚拟化虚拟服务器必须运行同一操作系统
- 裸机虚拟化:架构中的VMM也可以认为是一个操作系统,一般称为Hypervisor、Hypervisor实现从虚拟资源到物理资源的映射、Hypervisor实现了不同虚拟机的运行上下文保护与切换,保证了各个客户虚拟系统的有效隔离
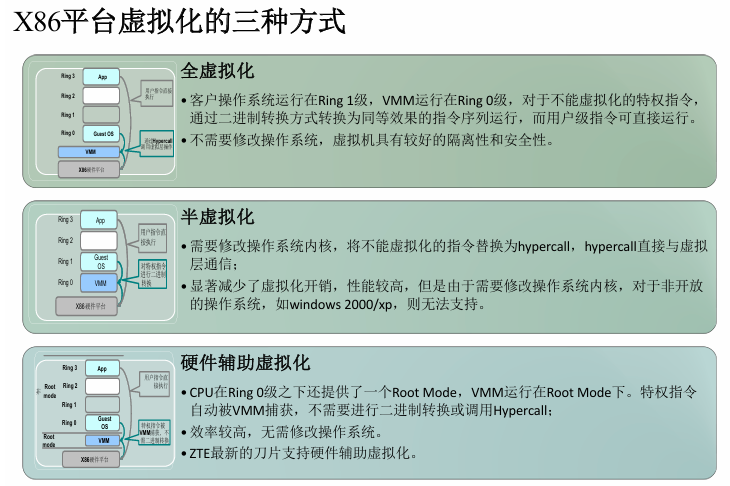
三种CPU虚拟化技术(全虚拟化、半虚拟化、硬件辅助虚拟化)
- 全虚拟化技术:VMM捕获客户操作系统异常,进行翻译、模拟的过程
- 半虚拟化:修改操作系统内核,替换掉不能虚拟化的指令,通过超级调用(hypercall)直接和底层的虚拟化层hypervisor来通讯。
- 硬件辅助虚拟化:CPU厂商支持,Intel 引入了 Intel-VT 技术,VMM运行 VMX root operation、客户 OS 运行在 VMX non-root operation模式
内存虚拟化的基本原理
内存虚拟化技术:把物理内存统一管理,包装成多个虚拟的物理内存提供给若干虚拟机使用,每个虚拟机拥有各自独立的内存空间。
- 客户机采用客户页表维护虚拟地址到客户机物理地址的动态映射;
- VMM负责维护客户机物理地址到宿主物理地址的动态映射;
IO虚拟化的概念
I/O设备虚拟化技术:把真实的设备统一管理起来,包装成多个虚拟设备给若干个虚拟机使用,响应每个虚拟机的设备访问请求和I/O请求。
虚拟机迁移、内存、网络、资源迁移
- 虚拟机迁移:将虚拟机实例从源宿主机迁移到目标宿主机,并且在目标宿主机上
能够将虚拟机运行状态恢复到其在迁移之前相同的状态,以便能够继续完成应用程序的任务。
- 预迁移、预定资源、预复制、停机复制、提交、启动
- 内存迁移: (虚拟机迁移最困难的部分)Push阶段、Stop-and-Copy阶段、Pull阶段。
- 网络迁移:在局域网内,可以通过发送ARP重定向包,将VM的IP地址与目的机器的MAC地址相绑定,之后的所有包就可以发送到目的机器上。
- 存储设备迁移:以共享的方式共享数据和文件系统、NAS(网络连接存储)作为存储设备共享数据。
- 虚拟机隔离:虚拟机之间在没有授权许可的情况下,互相之间不可通信、不可联系的一种技术。
Openstack的基本概念
旨在为公共及私有云的建设与管理提供软件的开源项⽬
三个主要的服务成员:计算服务(Nova)、存储服务(Swift)、镜像服务(Glance)
计算服务Nova:计算系统的结构控制器,其能根据用户需求来提供计算服务, 配置虚拟机规格,负责对虚拟机进行创建,并管理虚拟机使用的整个生命周期
存储服务主要包括Swift(提供镜像存储)、Glance(虚拟磁盘镜像目录分类管理及镜像库存储管理功能)和Cinder(数据块存储服务)
特点:⾼数据持久性、对称的系统架构、⽆限的可扩展性、⽆单点故障、简单可依赖
3. 分布式文件系统(谷歌文件系统GFS)
GFS的设计动机、假设条件
- 组件故障是常态而非例外;按照传统的标准,文件是巨大的(必须重新审视设计假设和参数,如 I/O 操作和数据块大小);大多数文件都是通过添加新数据而不是覆盖现有数据进行变异的(优化追加操作并保证原子性);共同设计应用程序和文件系统应用程序接口
- 组件故障率高、少量大文件、两种读数、将数据追加到文件的许多大型连续写入操作、为多个客户端提供定义明确的语、高持续带宽比低延迟更重要
GFS的接口及操作
- 文件系统界面 ;按目录分级组织,并用路径名标识;业务:常规操作 (创建、删除、打开、关闭、读取和写入文件)特别行动 (快照和记录附加)
GFS的基本架构
- 一个 GFS 集群 ;文件块;系统元数据 ;全系统活动
文件块、元数据的概念
- 全局元数据存储在主文件和块命名空间
单master的优化机制
- 最大限度地减少主节点参与:切勿通过 master 读取和写入文件数据;在缓存的信息过期或文件重新打开之前,不再进行 client-master 交互;在同一请求中请求多个 chunk
文件块的大小设计
- 存储为块的文件:固定大小 (64MB)
- 每个块副本都存储为普通 Linux 文件
- 根据需要扩展。
元数据的设计
全局元数据存储在 master 上
内存数据库(In-memory data structure):快、内存限制
数据块位置:不保留永久记录、启动时轮询块服务器、Heartbeat Message
操作日志:关键元数据更改的历史记录、在多个远程计算机上复制它、重播 + 检查点
系统交互活动:租赁与写一致性机制(流程)、数据流优化、原子记录追加等
- 租约和变更顺序:租约:在不同副本中保持一致的突变顺序、主要(带租约的副本)、最大限度减少管理开销
(60s) ;突变:更改内容或元数据的操作,如写入或附加操作
- 租赁与写一致性机制流程:1客户端向主站发送请求、2主站回复客户端、3客户端将数据推送到所有副本、4客户端向主设备发送写入请求、5主副本会将写入请求转发给所有辅助副本、6二级回复一级、7主站回复客户端
- 数据流优化:
- 充分利用每台机器的网络带宽:数据是沿着分块服务器链线性推送的
- 避免网络瓶颈和高延迟链路:将数据转发给尚未收到数据的 "最近 "机器
- 最大限度地减少延迟:通过 TCP 连接进行管道数据传输
- 原子记录方法:将大型写入操作分解为多个写入操作、一致性模型、记录附加( 至少一次原子式地将数据添加到文件中)、附加数据的大小 、保证数据作为原子单元至少被写入一次
- 快照:复制文件或目录树、写入时复制、快照后写入
Master的操作:副本放置的原则、垃圾回收机制、旧副本检测
副本放置的原则:多级高度分布、 最大限度地提高数据可靠性和可用性、最大限度地利用网络带宽、将大块复制分散到各个机架上
垃圾回收机制:重命名为包含删除时间戳的隐藏名称;如果文件存在超过三天,则应删除 ;使用 HeartBeat 消息删除块服务器上的副本
旧副本检测:块版本号 当主模块授予新租约时,增加租约;如果副本不可用,则不高级 ;在定期垃圾回收中删除过期副本
4. 分布式文件系统(小文件系统Haystack)
Haystack的设计背景
- Facebook 存储超过 2600 亿张图片、用户每周上传 10 亿张新图片、峰值时每秒提供超过 100 万张图片、用于图像服务的两种工作负载(个人资料图片 – 访问量大、尺寸较小 ;相册 – 间歇性访问,开始时较高,随时间减少(长尾))
- 需求:高吞吐量和低延迟、容错、成本效益、简单性
Haystack Directory的功能
- 提供从逻辑卷到物理卷的映射;在逻辑卷之间对写入进行负载平衡;确定照片请求应由 CDN 还是由 Haystack Cache 处理;识别只读的逻辑卷
Haystack Cache的功能
- 分布式哈希表,使用 photo 的 id 来定位缓存的数据;接收来自 CDN 和浏览器的 HTTP 请求;如果满足两个条件,则将照片添加到缓存...
Haystack Store的功能
- 每台 Store 计算机管理多个物理卷;可以仅使用对应逻辑卷的 id 和照片的文件偏移量快速访问照片;处理三种类型的请求(读取 写入 删除)
needle的结构、index file的结构
- 一个针(needle)的唯一标识是由它的 <Offset, Key, Alternate Key(备用键), Cookie>元组决定的,其中偏移量是指针在干草堆存储中的偏移量。
- 索引文件提供了在存储区中查找特定针所需的最少元数据
- 主要目的:允许将 needle 元数据快速加载到内存中,而无需遍历较大的 Haystack 存储文件
5. MapReduce
背景知识
- 大数据处理很困难,设计一个新的抽象化并隐藏实现的混乱细节!
Map和Reduce的基本概念
- Map:处理输入键/值对、生成一组中间对
- Reduce:合并特定键的所有中间值、生成一组合并的输出值
MapReduce的例子
- 有一个句子,我们想计算每个 word 的出现次数
- Map:遍历输入,并为每个单词返回一个 (
, 1) 元组。将相同的 key 分组并按 key 排序。 - Reduce:Sum每个列表中的值。
- Map:遍历输入,并为每个单词返回一个 (
- URL 访问频率计数:Map: <URL,1>Reduce: <URL, total count>
MapReduce实现的基本流程
- 将输入文件拆分为 M 个块,通常为 16 MB 到 64MB。在一组计算机上启动程序的多个副本。
- master 挑选空闲的 worker 并为每个 worker 分配一个 map 任务或一个 reduce 任务。有 M map 任务和 R reduce 任务要分配。
- 分配了映射任务的工作线程读取输入拆分的内容。中间键/值对缓冲在内存中。
- 缓冲对会定期写入本地磁盘,并通过分区功能分区到 R 区域。
- reduce worker 使用远程过程调用从 map worker 的本地磁盘读取缓冲数据。中间键按中间键排序。
- reduce 迭代排序的中间数据,并将 key 和值集传递给 Reduce 函数。Reduce 函数的输出将附加到此 reduce 分区的最终输出文件中。
- 当 map 任务和 reduce 任务全部完成后,master 唤醒用户程序。
容错机制、(注意Map任务和Reduce任务之间的不同)
- 工作线程故障(Worker Failure)
- 通过定期检测信号消息检测故障
- 重新执行已完成和正在进行的地图任务
- 重新执行正在进行的 reduce 任务
- 通过 master 提交任务完成
- 主站故障(Master Failure)
- 从最后一个 checkpointed 状态开始新副本(多主站)
- 中止 MapReduce 计算、客户端重试 MapReduce 操作(单主站)
任务粒度
- M 是Map块的数量。R 是 reduce 件的数量,实际边界:master 做出 O(M+R) 调度决策并将 O(M*R) 状态保存在内存中。
备份任务
- 工作程序速度较慢会显著延迟完成时间
- 其他作业消耗计算机上的资源。具有软错误的
- Bad 磁盘传输数据的速度很慢。
- 解决方案:在阶段接近尾声时,生成备份任务
- 先完成的任务“获胜“
- 显著缩短作业完成时间
6. Spark
Spark的设计动机
- 当前的大多数集群编程模型都是基于从稳定存储到稳定存储的无环数据流
- 对于重复重用一组工作数据的应用程序来说,非循环数据流效率低下:迭代算法(机器学习、图形) 、交互式数据挖掘工具(R、Excel、Python) 使用当前框架,应用程序在每个查询时从稳定存储中重新加载数据
RDD的基本概念、并行操作、共享变量
- Resilient distributed datasets (RDDs):弹性分布式数据集
。允许应用程序将工作集保留在内存中以实现高效重用;保留 MapReduce
的特性(容错性、数据局部性、可扩展性);支持广泛的应用程序
- 不可变的分区对象集合;computetheRDD从可靠存储中的数据开始;通过对稳定存储中的数据进行并行转换(map、filter、groupBy、join 等)创建;可以缓存以实现高效重用
- 并行操作:Reduce:在驱动程序中使用关联函数组合数据集元素 ;collect:将数据集的所有元素发送到驱动程序;foreach:通过 AUSER 提供的函数传递每个元素
- 共享变量:Broadcast变量(只读、UsedInMultiple 并行操作、分发给 worker 一次)Accumulators(工作只能通过关联操作添加,只有驱动可以读取)
Log mining的例子,容错机制
- 将错误消息从日志加载到内存中,然后以交互方式搜索各种模式;RDD 维护可用于重建丢失分区的世系信息
Logistic regression的例子
for (i <- 1 to ITERATIONS) {
val grad = spark.accumulator(new Vector(D))
for (p <- points) {
val s = (1 / (1 + exp(-w dot p.x) - p.y)
grad += s * p.x
}
w -= grad.value
}for (p <- points)循环中的代码会在Spark的多个工作节点上并行执行,这是通过RDD的并行操作实现的。每个节点处理数据的一个分区,并计算局部梯度,然后将结果汇总到累加器中。
7. Pregel 图计算
计算模型的基本概念(输入、输出、超级步、停止条件)
输入:有向图 ;每个顶点由一个顶点标识符唯一标识,该标识符与一个可修改的用户定义值相关联 ;每个有向边与一个源顶点、一个可修改的用户定义值和一个目标顶点标识符相关联
超级步:由全局同步点分隔;顶点并行计算;修改其状态或传出边的状态;改变图形的拓扑
停止条件:所有顶点同时处于非活动状态;没有传输中的消息
输出:顶点显式输出的值集;通常是有向图,但不是必需的
Pregel的计算过程:是由一系列被称为“超步”的迭代组成的。在每个超步中,每个顶点上面都会并行执行用户自定义的函数,该函数描述了一个顶点V在一个超步S中需要执行的操作。该函数可以读取前一个超步(S-1)中其他顶点发送给顶点V的消息,执行相应计算后,修改顶点V及其出射边的状态,然后沿着顶点V的出射边发送消息给其他顶点,而且,一个消息可能经过多条边的传递后被发送到任意已知ID的目标顶点上去。
当一个顶点不需要继续执行进一步的计算时,就会把自己的状态设置为“停机”,进入非活跃状态。
理解两个例子(Maximum value example, SSSP单源最短路径,包括代码理解)
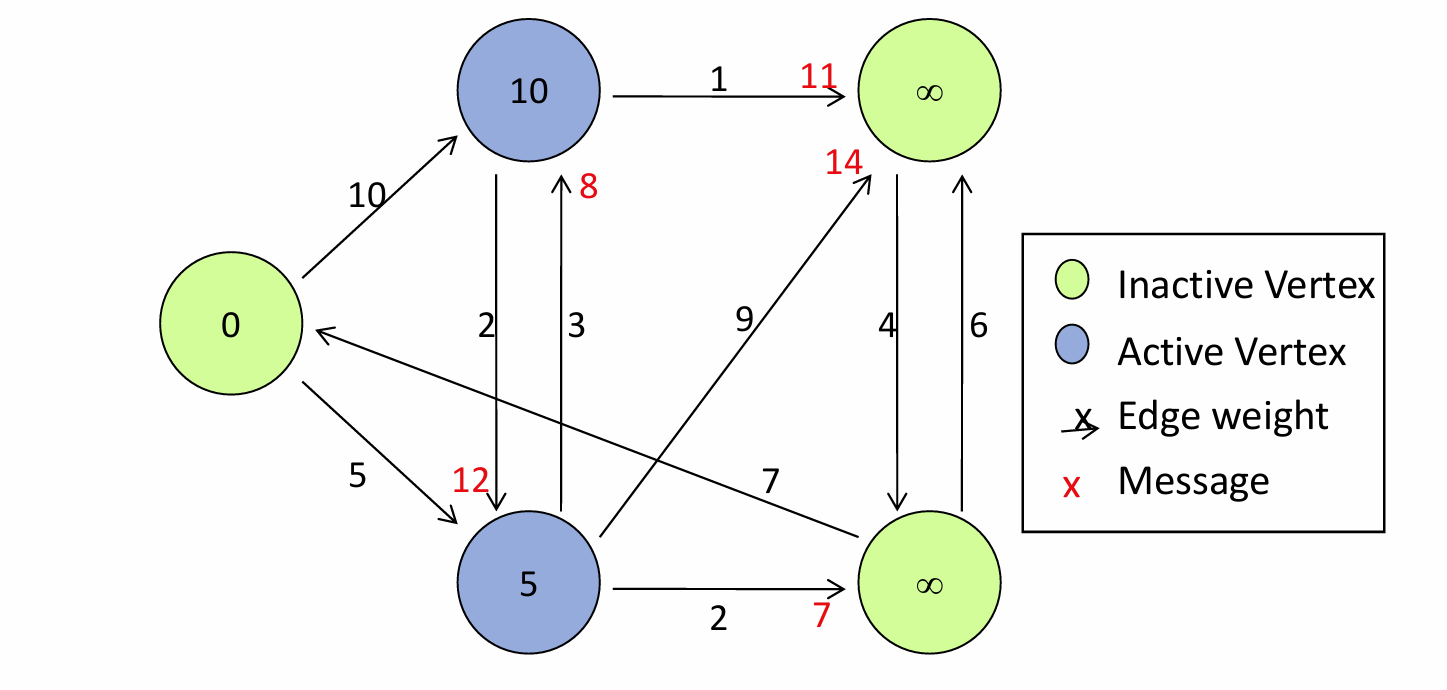
理解MapReduce和Pregel的不同
- 图形算法可以编写为一系列链式 MapReduce 调用
- Pregel:在执行计算的机器上保留顶点和边;只对消息使用网络传输
- MapReduce:将图形的整个状态从一个阶段传递到下一个阶段;需要协调链式 MapReduce 的步骤
Combiner函数
- Worker 可以组合其 vertices 上报的消息,并发出一条消息
- 减少消息流量和磁盘空间
pregel的实现流程
- 程序的许多副本开始在计算机集群上执行
- Master 对图形进行分区,并为每个 worker 分配一个或多个分区
- Master 还为每个 worker 分配一个 input 的分区
- Master 指示每个 worker 执行一个 superstep
- 计算停止后,master 可以指示每个 worker 保存其部分的 graph
容错机制: 局部恢复
- Checkpointing:主节点定期指示 worker 将其分区的状态保存到持久存储中
- 故障检测:使用常规的 “ping” 消息
- 恢复:主节点将图形分区重新分配给当前可用的工作线程、所有工作线程从最近的可用检查点重新加载其分区状态
- 受限恢复:记录传出消息、仅涉及正在恢复的分区
worker、master、aggregator的实现
- worker:维护其图形部分的状态、发送消息给另一个顶点
- master:协调工作人员的活动、维护有关计算进度和图形状态的统计信息
- aggregator:在 superstep 期间,worker 将提供给聚合器实例的所有值组合成一个 local 值,将部分缩减的聚合器减少为全局值
PageRank算法和二部图的实现
PageRank:用于根据对文档的引用数量和源文档本身的重要性来确定文档的重要性
- A = 指定页面; T1 …. Tn = 指向页面 A 的页面(引用); d = 阻尼系数,介于 0 到 1 (通常设为 0.85); C(T) = 链接数量; PR(A) = 页面 A 的 PageRank
\[ PR(A)=(1-d)+d\bullet(\frac{PR(T_1)}{C(T_1)}+\frac{PR(T_2)}{C(T_2)}+.......+\frac{PR(T_n)}{C(T_n)}) \]
Bipartite Matching:输入2 个不同的顶点集(L、R),边缘仅在该集之间
第一阶段:每个尚未匹配的左顶点向每个相邻顶点发送请求匹配的消息,然后无条件投票停止。 第二阶段:每个尚未匹配的右顶点随机选择收到的信息之一,发送信息批准该请求,并向其他请求者发送拒绝请求的信息。然后无条件投票停止。 第三阶段:每个尚未匹配的左顶点选择收到的批准信息之一,并发送接受信息。 第四阶段:未匹配的右顶点最多收到一条接受信息。它记录匹配的节点,并无条件投票停止
8.GraphLab
基于图的数据表示
- 具有与每个顶点和边关联的任意数据(C++ 对象)的图形。
更新函数
- 更新函数是用户定义的程序,当应用于顶点时,它会转换顶点范围内的数据
调度器
- 调度器确定顶点的更新顺序。该过程将重复,直到调度程序为空
- Round Robin:顶点按固定顺序更新
- FIFO:顶点按添加顺序更新
- 优先级:顶点按优先级顺序更新
一致性模型
- 对于每个并行执行,存在一个 update 函数的顺序执行,这会产生相同的结果。
- 运行相邻更新函数的处理器同时修改共享数据
- 保证所有更新函数的顺序一致性
- 如果两个顶点不共享一条边,则可以同时更新这两个顶点
Label Propagation的例子(标签传播算法)
9. Paxos
相关概念(问题描述、角色类型、工作环境)
Paxos旨在解决的是在一群可以提出值的进程中如何确保这些值中仅有一个被选中的问题。共识算法必须满足以下的安全要求:
- 只有已经被提出的值才可能被选中。
- 只能选择一个单一的值。
- 进程不能得知一个值已被选中除非它实际上已经被选中。
在Paxos算法中有三种类型的代理(角色):
- Proposers(提议者):负责提出值和尝试让这些值被接受。
- Acceptors(接受者):负责对提议进行投票,并最终决定哪些值被选中。
- Learners(学习者):负责了解哪些值最终被选定。
一个单独的进程可以同时扮演多个角色。
Paxos算法是在异步、非拜占庭模型下工作的,意味着:
- 各个代理的操作速度是任意的,可能会因为停止而失败,也可能会重启。
- 消息传递的时间可能是任意长的,消息可能会被复制或丢失,但不会被篡改。
算法描述(阶段1、阶段2)理解例子
阶段1: 准备(Prepare)阶段2: 接受(Accept)阶段3:Learn阶段
获取一个Proposal ID n,为了保证Proposal ID唯一,可采用时间戳+Server ID生成;
Proposer向所有Acceptors广播Prepare(n)请求(提议包含两个字段:[n, v],其中 n 为序号(具有唯一性),v 为提议值)
Acceptor比较n和minProposal,如果n>minProposal,minProposal=n(保证以后不会再接受序号小于 n1的提议。),并且将 acceptedProposal 和 acceptedValue 返回(包括 [no previous] 尚无提案);n<=minProposal,则丢弃该提议请求;
Proposer接收到过半数回复后,如果发现有acceptedValue返回,将所有回复中v最大的作为本次提案的v,否则可以任意决定本次提案的vv;
进入第二阶段,广播Accept (n,value) 到所有节点;
Acceptor比较n和minProposal,如果n>=minProposal,则acceptedProposal=minProposal=n,acceptedValue=v,本地持久化后,那么就发送通知给所有的 Learner;否则,返回minProposal。
提议者接收到过半数请求后,如果发现有返回值result >n,表示有更新的提议,跳转到1;否则value达成一致。
10. Chubby
Chubby cell的概念
- 副本集:放置以减少相关故障;
- 使用 Paxos 选择 master (主租赁):承诺不为主租约选择新的主租约 – 副本会定期续订主租约;
- 维护简单数据库的副本
- 只有 master 启动数据库的读取和写入:使用共识协议进行更新
- 用于故障副本的替换系统:从空闲池中选择一台新计算机 – 更新 DNS 表,替换 IP 地址 – 主轮询 DNS 并注意到更改 – 从备份和活动副本中获取数据库的副本
缓存机制
- 客户端缓存文件数据、节点元数据。内存中保存的直写缓存
- 失效:主服务器保留客户端可能已缓存的内容列表 – 写入区块,主服务器发送失效 – 客户端刷新更改的数据,使用KeepAlive确认 – 一轮失效,数据不可缓存
- 使数据无效但不更新:任意更新效率低下
- 严格一致性与弱一致性:较弱的模型更难为程序员使用;不想更改预先存在的通信协议
- 处理和锁定缓存:事件通知客户端有冲突的锁请求
会话机制
- 通过 KeepAlives 维护的会话;句柄、锁、缓存数据仍然有效;显式终止,或在租约超时后终止;租约超时提前;Master 提前租约超时;客户端立即发送另一个 KeepAlive;缓存失效搭载在 KeepAlive 上;客户端维护本地租约超时;本地租约到期时:禁用缓存、会话处于危险状态,客户端在宽限期内等待、重新连接时启用缓存;应用程序获知会话更改
Fail-over机制
- 已丢弃的内存中状态( In-memory state discarded);快速连任(Quick re-election);缓慢的连任( Slow re-election)
- 新当选主机的步骤:1. 选择新的纪元编号 2. 仅响应主机位置请求 3. 为数据库中的会话/锁建立内存状态 4. 响应KeepAlives 5. 向缓存发出故障转移事件 6. 等待确认/会话过期 7. 允许所有操作继续 新选主机的步骤(续):8.处理创建的故障转移前使用的主机——在内存中重新创建,响应调用——如果关闭,则在内存中记录 9.删除间隔后没有打开句柄的临时文件
11. Bigtable
数据模型(行、列、时间戳维度),以网页为例
Bigtable的数据模型是一种稀疏、分布式、持久化的多维排序映射,它以(行:字符串, 列:字符串, 时间戳:int64)-> 字符串的形式组织数据。下面我们将以存储网页为例来解释这个数据模型中的各个维度。
行 (Row)
- 键:行键是任意的字符串,长度可达64KB,但通常会更短。在网页的例子中,行键可以是反转后的URL(例如,com.example.www会被存为www.example.com),以便于按域名进行排序。
- 操作:对同一行的所有操作都是原子性的。
- 排序:行按照字典序排列。具有连续键的行构成一个Tablet,这是Bigtable分布和负载均衡的基本单位。
列 (Column)
- 分组:列被分成若干个列族(column families),每个列族是一个访问控制单元。例如,对于网页,可能有多个列族来分别存储页面内容、元数据、链接等不同方面的信息。
- 类型:所有在一个列族内的数据都应该是同一种类型。
- 创建:必须先创建列族才能向其中写入数据。
- 数量:不同的列族数量应该保持较小,并且很少改变。
时间戳 (Timestamp)
- 键:时间戳是一个64位整数,用来索引同一行同一列的不同版本的数据。
- 分配:时间戳可以由Bigtable自动分配(精确到微秒级别),也可以由客户端应用程序指定。
- 顺序:数据按照递减的时间戳排序,即最近的版本排在最前面。
- 垃圾收集:为了管理版本历史,Bigtable允许设置每列族保留的最大版本数或一定时间段内的版本,超出范围的数据将被清理。
SSTable的概念及结构
它是一种持久化、不可变且有序的键值对存储结构。每个SSTable由一系列按照字典序排序的键值对组成,这些键值对被组织成多个块(block),通常每个块大小为64KB。
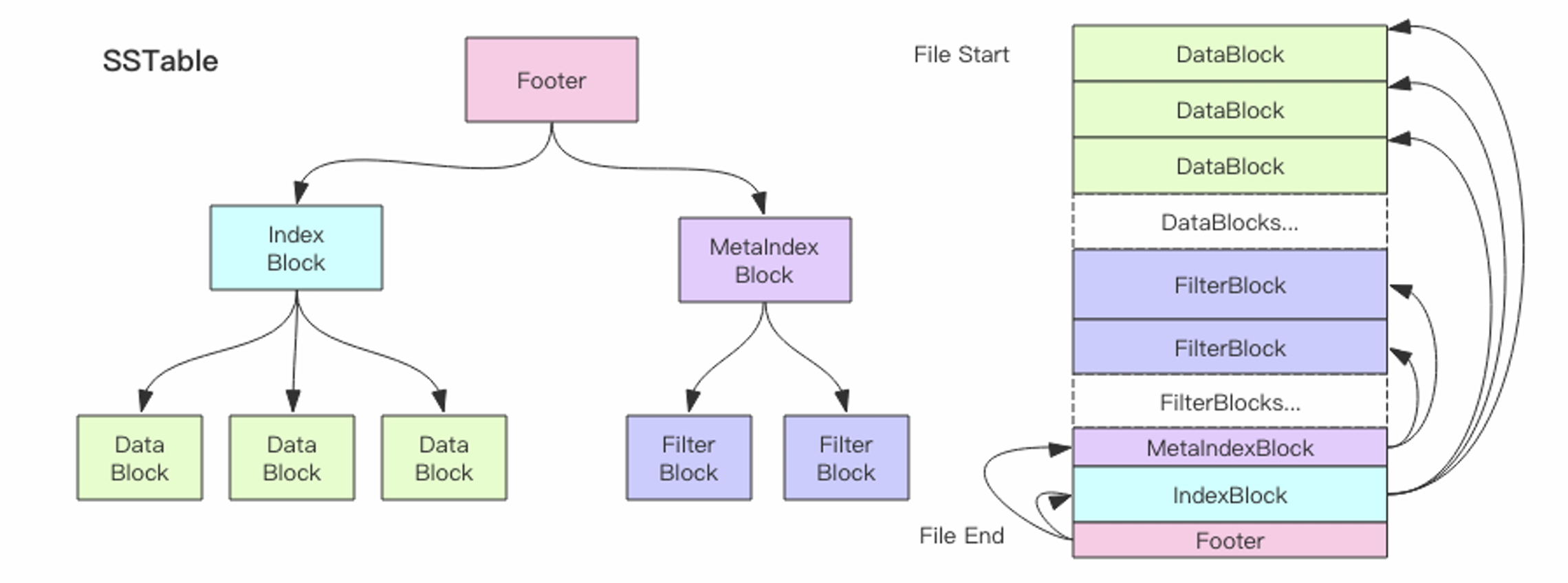
Chubby和Bigtable的联系
Chubby作为Bigtable的外部依赖,提供高可用且持久的分布式锁服务,各种任务(提供命名空间,并保证任何时候最多一个活动服务器的读/写的原子;发现 Tablet 服务器并最终确定 Tablet 服务器死亡)。如果 Chubby 长时间不可用,Bigtable 将不可用。
Tablet的定位(三层架构)
- 根表 (Root Tablet):存储了所有METADATA表的Tablet位置信息。
- 元数据表 (METADATA Tablet):每个METADATA行存储了一个Tablet的信息(包括标识符和结束行键),并且每行大约占用1KB内存。为了防止METADATA表过大,对其大小有一个适度限制,比如128MB。
- 用户数据表 (User Data Tablet):这些Tablet存储实际的用户数据。当需要访问某个具体的Tablet时,首先会查询根表以获取对应的METADATA表位置,再从METADATA表中查找目标Tablet的具体位置。
Tablet的分配
- 跟踪在线状态:主服务器持续监控存活的tablet服务器集合以及当前Tablet到tablet服务器的分配情况。
- 分配任务:当有新的Tablet需要分配或现有分配发生变化时,主服务器会向相应的tablet服务器发送加载请求。
- 负载均衡:主服务器还负责检测集群中的负载状况,并根据需要重新分配Tablet以保持各服务器之间的负载均衡。
- 发现与终结:主服务器通过监视Chubby目录来发现新加入的tablet服务器,并在服务器失效时做出响应。
Tablet的服务(读、写、恢复)
- 写操作:在写入之前,系统会检查输入格式是否正确并验证权限。有效的变更会被记录到提交日志中,随后插入到memtable里。
- 读操作:读取前同样进行格式和权限检查。读取是在SSTable和memtable合并视图上执行的,这样可以确保即使数据分布在多个文件中也能高效地形成结果集。
- 恢复操作:当Tablet重启时,它会从METADATA表读取元数据,加载SSTable索引到内存,并重建自上次持久化点以来的memtable,从而恢复到最新的状态。
Compaction的三种类型及概念
- Minor Compaction:将memtable转换为一个新的SSTable,减少内存使用量,并降低重启时的日志流量。
- Merging Compaction:减少SSTable的数量,这是应用版本控制策略(如保留最近N个版本的数据)的好时机。
- Major Compaction:是一种特殊的合并压缩,最终只产生一个SSTable,里面仅包含未被删除的有效数据。这种压缩有助于清理不再需要的数据,并提高查询效率。
12. 并行计算
并行计算的定义
- 同时使用多种计算资源解决计算问题。问题被分为离散的部分;每个部分进一步分解为离散的指令; 每个部分指令同时在不同处理器执行;总体控制和协调机制
并行计算的发展
- 始于70年代:1946年第一台计算机ENIAC,1972年第一台并行计算机ILLIAC IV,向量机Cray-1(一般将Cray-1投入运行的1976年称为 “超级计算元年”)
- 80年代百家争鸣:早期:以MIMD并行计算机的研制为主;中期:共享存储多处理机SMP;后期:具有强大计算能力的并行机
- 90年代体系结构框架趋于一统:DSM分布式共享存储, MPP大规模并行处理结构, NOW工作站机群
- 2000年至今前所未有大踏步发展:Cluster机群,Constellation星群, MPP专用高性能网络
- 目前典型的并行系统组成(引入异构架构)
- 并行计算发展水平的标志:超级计算机,性能是以每秒浮点运算(FLOPS)来衡量
- Top500趋势:国家对比、算力架构对比、互联网络对比、超算架构对比、制造商对比、百亿亿次(EFlop)、E级超算计划
并行程序的性能评价
- 加速比:\(S(p)=\frac{T_s}{T_p}\),\(T_s\)是最佳串行算法的执行时间,\(T_p\)是使用p个处理器时的执行时间。无法达到的原因:不能并行化处理器空闲、并行需要额外的计算(同步成本)、进程之间通讯成本(主要因素)
- 系统效率\(E(p)=\frac{T_s}{p\times T_p}\)
- Amdahl定律:并行化后加速比计算公式与理论上限, f 表示程序中不可以被并行化的部分所占的比例。$S(p)= = $ ,随着处理器数量的增加,对并行效 率的提升会固定在一定比例\(S(p)_{p\to\infty }=1/f\)
- Gustafson定律: 研究在给定的时间内用不同数目的处理器能够完成多大的计算量\(S(p)= \frac {ts+p\times t_ {p}}{t_ {s}+p\times t_ {p}/p} = \frac {t_ {s}+p\times t_ {p}}{t_ {s}+t_ {p}} =f+p \times (1-f)\)
- 可扩展性:性能随处理器数的增加而按比例提高的能力
- 强可扩展性:问题规模不变,处理器的数量增加。线性扩展(加速比等于处理器的数量)很难实现,
- 弱可扩展性:随着处理器的增加,问题的规模同比增加。线性扩展(负载的增加,执行时间保持不变)更容易实现。
- 时间复杂度:\(T_p = T_{comp}+T_{comm}\),计算时间+通信时间;\(T_{comm}=\sum T_{startup}+nT_{data}\) 信息延迟+信息数据量×单位数据的传输时间
MPI并行编程的6个常用接口
MPI是一个消息传递接口标准
- MPI_INIT:MPI初始化。初始化MPI并行程序的执行环境,其它MPI函数之前被调用,并且在一个MPI程序中,只能被调用一次
- MPI_FINALIZE:结束MPI系统。清除MPI环境的所有状态。
- MPI_COMM_RANK:返回本进程在指定通信域中的进程号,将自身与其他进程区分
- MPI_COMM_SIZE :返回指定通信域所包含的进程数,确定自身完成任务比例
- MPI_SEND:用于发送一个消息目标进程。阻塞型消息发送接口。点对点通信是MPI通信机制的基础。
- MPI_RECV:用于从指定进程接受一个消息。阻塞型消息接收接口。
MPI消息的结构
- 消息缓冲:消息的内容。由三元组<起始地址,数据个数,数据类型>标识
- 消息信封:消息的接收/发送者地址。由三元组<源/目标进程,消息标签,通信域>标识
- 消息类型分为预定义类型和派生数据类型。消息标签用于接收者区分这两个消息